Analyzing User Reviews to Promote Customer Retention & Acquisition
Quick Summary: In this project, we analyzed thousands of user reviews left on the Google Store for the Netflix application in order to locate strengths and weaknesses to help us understand how to address customer frustrations and better market Netflix to the broader public amidst heightened competition.
We did this using Natural Language Processing (NLP) to train a binary classifier capable of categorizing Negative and Positive reviews, and then deployed Latent Dirichlet Allocation (LDA) to extract themes and topics to inform our marketing strategies moving forward.
Introduction
Current State of Streaming
Though Netflix has long dominated the OTT market (“Over-the-Top”, refering to the method of delivering content over the internet), the landscape of streaming services has drastically changed over the last few years, and with it, the challenges that Netflix faces. One of the most formidable of these challenges is the entry of legacy media companies, such as Disney and NBCUniversal, into the OTT market, as they are able to leverage their deep content libraries to attract subscribers to their own services.
According to Whip Media’s 2023 US Streaming Satisfaction Survey, there is persistent weakening trend among platform leaders, as Netflix “continues to decline in most measurements of satisfaction, while still holding on to the top rankings in the categories of user experience and programming recommendations.”
A 2023 piece by Variety surveying 40 Hollywood insiders about their experience using the numerous streaming platforms available to the public, or more specifically, “the way consumers interact with an app or website before, during and after they watch that content”, found that “Netflix was most widely regarded as having the best UI [User Interface], with several comments about how intuitive and aesthetically pleasing the platform is.” Another strength of Netflix’s is its sophisticated recommendation system, sometimes refered to as “digital nudging”, which plays an important role in minimizing customer churn.
Another aspect that gives Netflix a competitive advantage over other streaming platforms is the state of its global reach, as it currently operates in more than 190 countries.
While other streaming services can leverage content exclusivity to attract subscribers, Netflix’s library is not as deep or expansive, at least for the time being. However, Netflix’s technical superiority in UI and digital nudging gives it an indispensable competitive edge against its competitors, and must continually adjust its platforms and respond to the faults which can drive away consumers and subscribers.
Business Problem
Considering the strengths and weaknesses of Netflix outlined above, we need maintain our competitive edge against other streaming platforms by better understanding which aspects of our platform frustrate our customers and which aspects resonate well with subscribers.
In other words, both Positive ad Negative reviews matter equally for our purposes.
We can do so by taking a look at reviews written over the past two years (2023-2025), to ensure that our insights are timely and relevant, as there is little point in working with older criticisms that may have already been addressed.
Put another way, we seek insights pertaining to the following:
- Customer Retention, and why some users are unhappy with Netflix and may cancel their subscriptions.
- Customer Acquisition, and identify what it is that people currently appreciate about Netflix so it can inform our promotions and marketing.
What this requires of us is:
- To build a binary classification model that can deploy Natural Language Processing (NLP), or more specifically, Sentiment Analysis on the user reviews, and use that insight to predict whether the review is positive or negative. This can be done through traditional supervised learning models, such as Logistic Regression, Random Forest Classifiers, SVM, etc.
- Apply Latent Dirichlet Allocation, or
LDA, to both groups of positive and negative reviews to identify trends and themes that will inform the actions we take.
In this way, we will be better equipped to provide solid business recommendations regarding subscriber retention as well as more effective marketing campaigns.
Data Understanding & Preparation
The dataset we will be working with was pulled from Kaggle and contains more than 129,000 reviews dating back to 2018, which is 7 years as of the time of writing. This dataset is updated daily, and the data contained within it is up-to-date as of 2 March, 2025.
Of the 8 columns contained in this dataset, the following are of particular or potential interest to us, pending further investigation:
content, which contains the text of the user review. We will use this column for our NLP and Sentiment Analysis.# score, which contains a discrete (categorical) numeric rating on a scale of 1-5. This will serve as our Target column whose Labels we will predict based on the the text of the user reviews.# thumbsUpCount, which tells us how many ‘thumbs up’ each user review received from other reviews, potentially indicating the relative significance of different reviews since a higher count of thumbs up would indicate the review resonated with other users.at, telling us the date the user review was created. We will be looking to filter our data so that we can focus on reviews produced over the past year 1-2 years, or since 2023.
Features
We will use the text contained within the content column to produce features for our classifier by vectorizing the text using Term Frequency-Inverse Document Frequency (TF-IDF), which is a useful strategy for determing the relative significance of terms used in the user reviews by weighing the frequency of their appearances within a review against their relative rarity across all reviews in consideration.
We will also factor in # thumbsUpCount in our modeling, so that our models can assign more significance to reviews that received more thumbs ups from other users, as we can reasonably assume that those reviews resonated with others.
Targets
The # score column will be used as our Target column by combining the low ratings (1 and 2) as a Negative class and combining the positive reviews (4 and 5) as a Positive class, and turning these classes into binaries: 0 for Negative, 1 for Positive.
We will be disregarding the ratings of 3 as we want a clear understanding of what makes a review strictly negative vs. strictly positive, and a middle of the road review of 3, as insightful as its content may be, would hinder our ability to understand the division of these sentiments.
Class Distribution
The imbalance in the distribution of our Negative and Positive classes is not too heavy, with a skew towards Negative.
- Negative: 61%
- Positive: 39%
We can hopefully minimize the impact of this imbalance through the Feature Engineering outlined above, and by tuning the hyperparameters of our models.
Success Metrics
In order to evaluate the performance of our models, we will be using the F1 Score, which is the harmonic mean between the rates of False Negatives and False Positives generated by our models.
It will additionally be useful in this case since False Negatives are not necessarily more detrimental to our purposes than False Positives, since as we argued above, both Positive and Negative reviews are of value to us.
Due to the slight class imbalance described above, this score would be more useful than a more general Accuracy score.
Model Selection
We will be deploying three models:
Multinomial Naive Bayes(Multinomial NB), which will serve as our baseline model. This model is relatively fast and works well with text data, though it tends to struggle with complex patterns between data.Logistic Regression, which is a robust choice for binary classification, as it handles correlated features well, and can balance Precision (rates of False Positives) and Recall (rates of False Negatives).LightGBM(LGBM), which is a powerful tree-based model that handles complex patterns effectively, and performs well with imbalanced data, though it tends to be slower than alternatives.
Cleaning the Dataset
Before we can begin modeling, we need to clean our dataset through the following steps:
- Removing null values.
- Removing unnecessary columns.
- Narrowing the dataset so it contains user reviews from 2023 onwards.
- Fixing spelling errors in content column.
- Consolidating the values within the Target column (
# score) so they are binary.
Feature Engineering
Factoring in Thumbs Up counts
The data contained in the thumbsUpCount column can help us determine relative significance of different user reviews: reviews with high thumbs up counts are probably more significant than reviews with 0 thumbs ups.
Since the distribution of this column’s values are all over the place, we scaled this column to ensure proper weight is given to reviews with more thumbs up without allowing outliers to dominate our models’ performances.
Since our column is heavily skewed to the right (disproportionate number of reviews with 0 thumbs up, with a few reviews having a high number of thumbs up) we will use log transformation to normalize this column in a way that does not overstate extreme outliers. Specifically, we will use log1p() to handle the large number of 0 counts.
Splitting the Data
As is common practice, we split our dataset into three sets:
- Training set, to train our models.
- Validation set, to evaluate the hyperparameter tuning we perform on the models.
- Test set, which is unseen data that will be a final test of our models’ capabilities.
Custom Transformer
We created a custom transformer, TextPreprocessor, which lowercases the text, removes special characters, tokenizes the text, removes stop words, and lemmatizes the text. This transformer will be used in our pipelines to prepare our text data to be processed by the models.
Pipelines
We prepared three pipelines, one for each model we will be deploying, to ensure systematic application of our steps and prevent data leakage.
These pipelines include two main steps:
ColumnTransformerthat will run our TextPreprocessor on our text, vectorize that text for TF-IDF, and combine these vectors with our thumbs_up_log column to be run in the model.Classifierwhich will run our models.
Modeling
Our untuned models all performed resonable well in terms of F1 score:
- MNB (baseline) — 83%
- LogReg — 86%
- LGBM — 84%
As we can see, our untuned Logistic Regression model performed best with an F1 score of 86%.
Tuning Hyperparameters
To see if we can boost the models’ performances, we attemped to tune their hyperparameters using RandomSearchCV.
In addition to tuning the models’ parameters, we also tuned parameters for the vectorizer, notably in introducing bigrams and trigrams, which essentially represent word pairings of two or three words as the added context can be helpful as opposed to considering each word in isolation.
For convenience, we saved the tuned models using joblib for easy loading and to save time when this notebook is run in the future. These saved models can be accessed in the tuned_models folder on this GitHub Repo.
Results
Tuning the hyperparameters did not improve our models’ performances by too much, between 1-2% for each model, but this is because our untuned models performed reasonably well in the first place, indicating we had hit a ceiling with how much we can improve the models performances without more substantive changes to the data and data processing.
Below is a bar chart of each model’s performance on the test data:
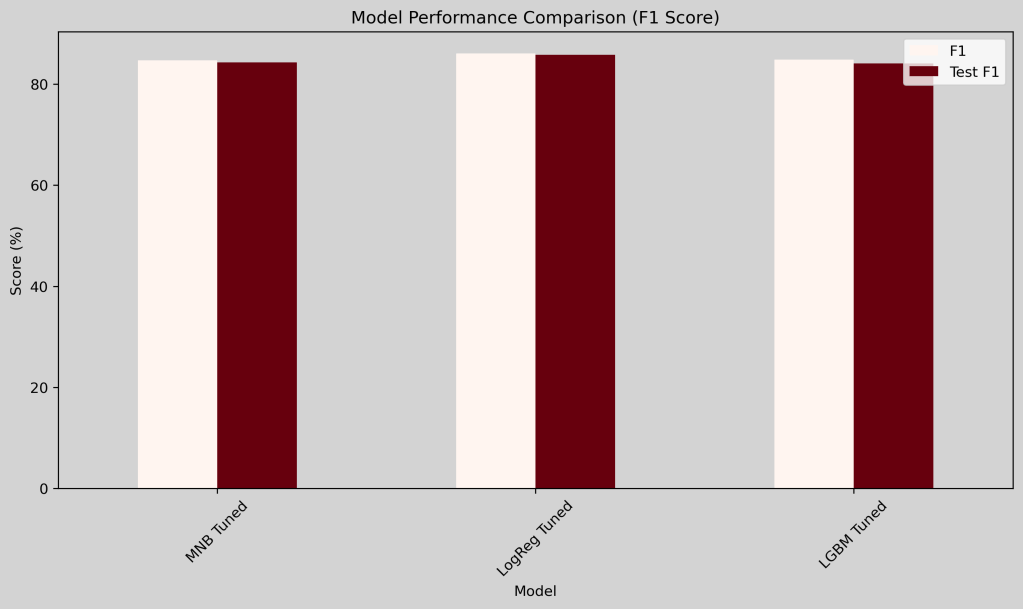
We can see above more strikingly that all our models performed well, with the tuned LogReg model performing the best with an 86% F1-Score on the testing data.
Let’s take a more detailed look at our tuned LogReg’s performance:
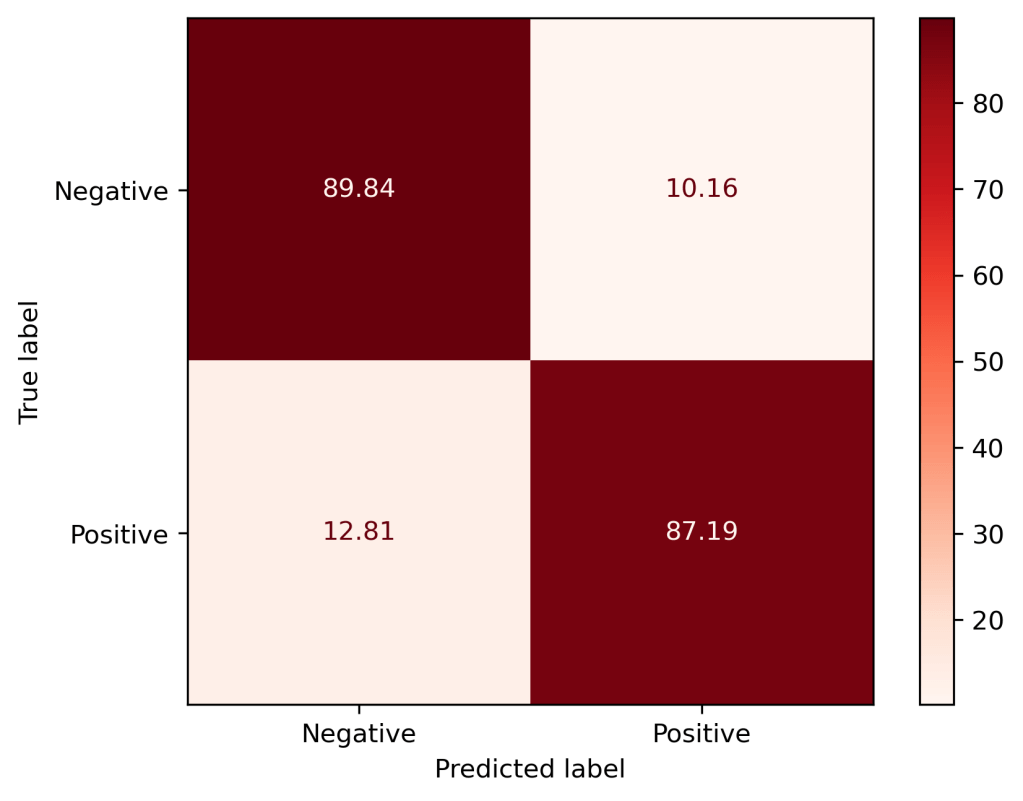
The top right corner shows that 10% of the negative reviews were incorrectly labeled as Positive, and 13% of the Positive reviews were incorrectly labeled as Negative.
However, as you can see in the top left corner, our model was about 90% successful in predicting Negative reviews, and in the bottom right corner, we were 87% successful in predicting Positive reviews.
What this tells us is we were correct in assigning weight to the Thumbs Up column and were able to account for the class imbalance relatively well, though there still is room for improvement.
LDA: Sorting Reviews by Topics
Next we sorted our data to see if we can learn of any trends or themes across the reviews.
For this, we used Latent Dirichlet Allocation, or LDA (documentation here), which is a useful unsupervised topic modeling algorithm used to sort documents and data according to topics, and can help find hidden themes within texts.
We did this through the following:
- Use our tuned LogReg model pipeline on the entire cleaned dataset to create a new column for predicted sentiment,
pred_sent. - Extract the Positive and Negative reviews sorted by our model into separate lists.
- Apply
LDAon both the Positive and Negative sets of reviews. - Analyze the topics and themes generated by
LDA.
Topic Analysis
LDA provided us with 5 approximations for topics each across the Positive and Negative reviews by identifying most consistent and recurring words and grouping the reviews together acccordingly. By taking a look at the words gathered, we surmised the following themes and trends contained in the sentiments expressed:
🔵 Positive Reviews
Topic 0 — Quality & Experience: People praise the series, anime, Hindi content, and dubbed options.
Topic 1 — Love for Netflix: Users express love for Netflix, favorite shows, and positive emotions.
Topic 2 — Functionality & UI: Positive mentions of the Netflix app being excellent, friendly, etc.
Topic 3 — Content & Features: Appreciation for series, episodes, games, and anime.
Topic 4 — Usability: Users highlight the platform, video quality, OTT experience, and entertainment.
🔴 Negative Reviews
Topic 0 — Account & Password Issues: Complaints about password sharing, login problems, and sign-in issues.
Topic 1 — Pricing & Payment: Users dislike high prices, payment issues, and ad-based subscriptions and related subscription tiers.
Topic 2 — Content Availability & Quality: Frustration with game selection, limited language options, and missing series.
Topic 3 — App Performance Issues: Frustration with bugs, crashes, playback errors, and loading issues.
Topic 4 — Household & Sharing Restrictions: Complaints regarding new password-sharing policies and related charges.
Though these are rough approximations, they indicate where we can intervene to prevent customer churn and how we can promote Netflix to gain new subscribers. Additionally, they indicate points for further investigation to flesh our strategy out in a more cohesive and in-depth way.
Conclusion
We were able to apply our finalized model, the tuned Logistic Regression model, on our entire cleaned dataset, and used our categorizations to generate topics through applying Latent Dirichlet Allocation, or LDA. In so doing, we were able to gain deeper insight into the reviews and can surmise action items and next steps moving forward to further deepen this line of investigation.
Evaluation
Despite a class imbalance in our Target, we successfully built a tuned Logistic Regression model capable of categorizing user review sentiment as Positive or Negative with a respectable F1 score of 86% through Feature Engineering (namely, factoring in the significance of Thumbs-Up counts for reviews) and tuning the model’s hyperparameters.
This F1 score tells us that our model was successful at striking a balance between preventing both False Negatives and False Positives, which for our stated purposes are equally important as we are trying to both find action items to prevent customer churn as well as find positives to promote our platform and gain new subscribers.
After running this model on our entire cleaned dataset, we used LDA to approximate themes and trends across the reviews, and found the following:
Positive Themes: What Users Love
Content Quality & Variety — Users appreciate Netflix’s series, anime, and dubbed content, particularly Hindi and other regional options.User Experience – Many users find the app’s usability to be easy and smooth. Favorite Features – Users praise OTT convenience, video quality, and diverse content options.
Negative Themes: Points for Growth
Pricing & Subscription Complaints – Users reacted negatively to high costs, payment issues, and ad-based plans and tiers. Password Sharing Restrictions – Related to the above point, many are frustrated with household-sharing limitations and extra charges. App Performance Issues – Many users complained about login errors, bugs, playback problems, and other technical issues. Content Gaps – Some users feel regional content and series availability are lacking.
Limitations
Neutral Reviews — Our modeling and analysis were limited by the fact that we chose to ignore Neutral reviews, and focus only on Positive and Negative sentiments. This decision was taken to create the most competent binary classifier possible, and the impressive results speak for themselves. However, our despite our solid insights gained, we could potentially go further by factoring in sentiments that are more mixed, as many Negative and Positive feedback can be gained by considering Neutral reviews.
Foreign Language Reviews — In our investigation and modeling, we found a recurrence of foreign words, namely Hindi though other languages were included as well. Though this limitation did not hinder our models’ abilities to classify the reviews too heavily, it did limit our ability to investigate the reviews more thoroughly, and if we were able to conduct NLP with foreign languages such as Hindi, we no doubt would have an even more robust model and analysis.
Recommendations
According to the insights laid out above, we recommend the following:
A) Customer Retention
- Improving Pricing & Subscription Flexibility — We may be able to reduce customer churn by offering more affordable regional pricing tiers, and by improving our communication on these ends.
- Addressing Password-Sharing Concerns — We should look into plans that are more family-friendly and reasonably flexible on the matter of multi-household use.
- Improving Communication — Customer dissatisfaction can be mitigated by improving our communication regarding some of the recurring issues such as pricing, subscription flexibility, and password-sharing concerns, and why these measures are deemed necessary and beneficial to the user’s experience.
- Enhancing Performance & Stability of the App — We should prioritize addressing technical issues such as playback errors, login issues, and loading issues, and look into implementing more effective in-app error resolution tools.
B) Promotion to Gain New Subscribers
- Expanding Regional Content — As we seek to cement and expand our global reach, we should invest in regional series and diverse language-based content. It would be particularly strategic for us to invest in promoting popular subbed and subtitled foreign-language content more consistently and effectively.
- Capitalizing on Netflix’s Strengths in Advertisements — Creatively blending the following aspects in a new promotional campaign:
- Variety and quality of our content, particularly regional content to expand our global reach.
- Usability and technical superiority, especially in comparison to our competitors.
Next Steps
These user review analysis techniques can be strengthened by factoring in Neutral Reviews and we recommend investing resources in developing models capable of accurately doing so.
Further, we urge the company to expand our NLP capabilities to include other languages, in order to more effectively and consistently respond to the praise and complaints brought by our global audience.
We should also consider partnering with regional and foreign-language streaming platforms like Shahid to push our global reach further.
